
Vaibhav Verma
Written in collaboration with : Ashish Kumar & Shubham Sharma
Abstract:
Salesken tries to seek order in randomness and brings out the best from a sales conversation that most of us think is unstructured. Here at Salesken, we make use of Artificial Intelligence and Machine Learning to bring this to reality. In this article, we present the detailed roadmap and goals that we want to achieve during the course of the next 18 months. This will cover different aspects of Conversation AI and the final outcomes of the approaches that will be followed.
Introduction:
The task of understanding a sales conversation requires a lot of domain expertise which is not a scalable option if our target audience has a very wide spectrum. By this, we mean that for any new customer that we onboard who might belong to a new domain we also need to bring in a new domain expert to define the way sales conversations flow in those fields.
The other and more scalable method is to rely on the past data and create our own custom conversation understanding system that can make sense and assign appropriate labels to each stage of the conversation. It will also be able to guide the sales agent toward the convergence of the call. But this requires a complete journey to be traveled before it sees the limelight.
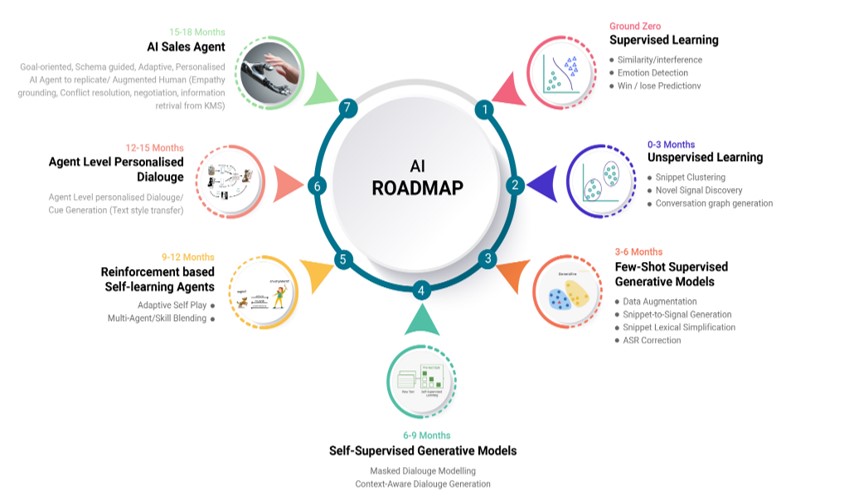
This roadmap will lay out all the intermediate steps of this process which will include seven stages that are as follows:-
- Supervised Learning
- Unsupervised/Semi-supervised Learning
- Few-shot Supervised Generative Models
- Reinforcement based Self-learning AI Agents
- Agent-level personalised Dialogue/cue generation(Text style Transfer)
- AI Sales Agent( Goal-oriented, Schema-guided, Adaptive, personalized AI agent to replicate/Augment Human sales agent )
Apart from these seven major categories we also need to cover a few other subtasks that do not fall under any of these categories but are important for the smooth functioning of any machine learning and data science project.
- Data collection and processing pipeline
- Model versioning and management system
- MLOps framework
Terminology Used:-
- Snippet:- A phrase or utterance of a speaker.
- Speaker:- It can be a sales agent or a customer (lead).
- Playbook dimensions:- These are the different states of a sales conversation and can broadly be divided into 6 categories:-
- Introduction:- At this stage of a sales call, the agents introduce themselves to the customer which may include the introduction of the organization they are calling from, their reason for calling, and other informal discussions to engage the customer.
- Lead Qualification:- In this section of the call the agent tries to investigate whether the lead is a potential candidate to become a customer or not by mapping the needs of the customer with their products, checking if the lead has an interest in a specific product and if yes then how urgent the customer needs it. The Agent might also check the authority of the lead to make the final decision and if the lead has sufficient budget/resources for deal finalization.
- Solutioning:- Here the agent tries to pitch the product to the customer by explaining the features of the product, ROI explanations, and other benefits of using the product.
- Objection Handling:- There can be a wide variety of objections that the customer can raise ranging from the price of the product to competitors. If such objections are raised then the agent tries to handle them with appropriate resolutions.
- Next Steps:- It is always not possible to sell a product in just one sales call, there might be situations where the agent needs to set up different stages like a product demonstration, webinar, etc. In such cases, the agent creates the next step of the task that has to follow for the lead conversion.
- Soft Skill:- An agent must also possess some soft skills for a quality conversation with the customer. These skills include Politeness, Empathy, Banter, Anchoring, Social Proof Negotiation.
- Signals:- These are the set of sentences that are mapped with playbook dimensions that need to be captured during a sales conversation. Each organization will have its unique signals set.
- Cue:- A hint or message shown to the agent during the sales conversation to assist the agent.
Workflow:-
This section gives a detailed explanation and objectives of the workflow to be followed for the fulfillment of the above-mentioned tasks.
1. Supervised Learning (Ground Zero):
Supervised learning is a machine learning technique of understanding the patterns from data using input and an output pair. The machine learning algorithm also known as a model, learns the objective function with the help of labeled data, and once the objective function is learned the algorithm can be used to predict the output on values that are never seen before.
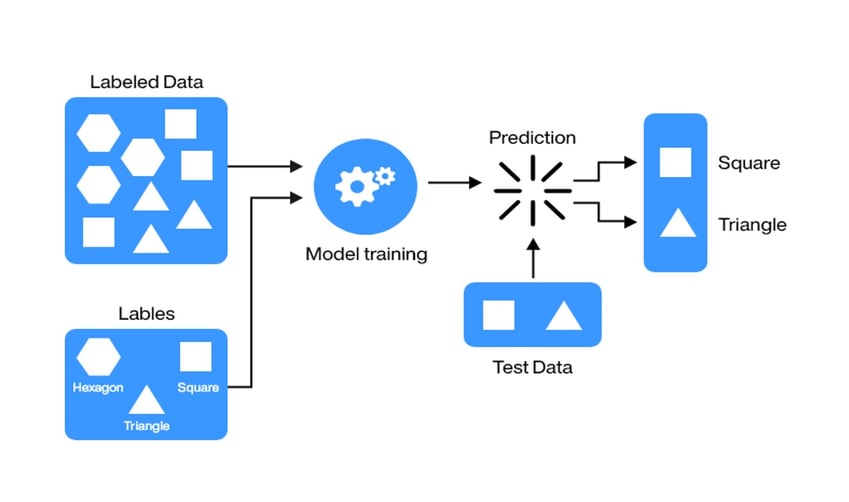
The different problem areas that will be covered under this technique are as follows:-
Similarity/Inference of sippets:-- The Conversation AI models that we build are very much capable of understanding the lexical and semantic meaning of sentences.
- Using these models predefined signals are mapped with the snippets of the agent and the customer by checking the similarity difference of the two sentences.
Emotion Detection:-
- In this problem statement, we try to find the emotions that are conveyed by either the agent or the customer using Language models (models that understand a language) with additional features of classifying the human emotions such as happiness, sadness, anger, fear, politeness, etc
- Once all the snippets are tagged with emotions an overall emotion profile of each user can be created for the sales call.
Lead Win/loss Prediction:-
- This area tries to predict if the lead will buy the product or not and get converted to a customer.
- Using the information gained by signal and emotion tagging a general interference can be created about the success of the sales conversation.
- The model used for this task is trained using the CRM data of the customers.
2. Unsupervised/Semi-supervised Learning (0-3 months):
Unsupervised Learning is the machine learning technique in which the user does not need to supervise the model. Instead, it allows the model to work on its own to discover the patterns and information that were previously undetected. It mainly deals with the unlabelled data.
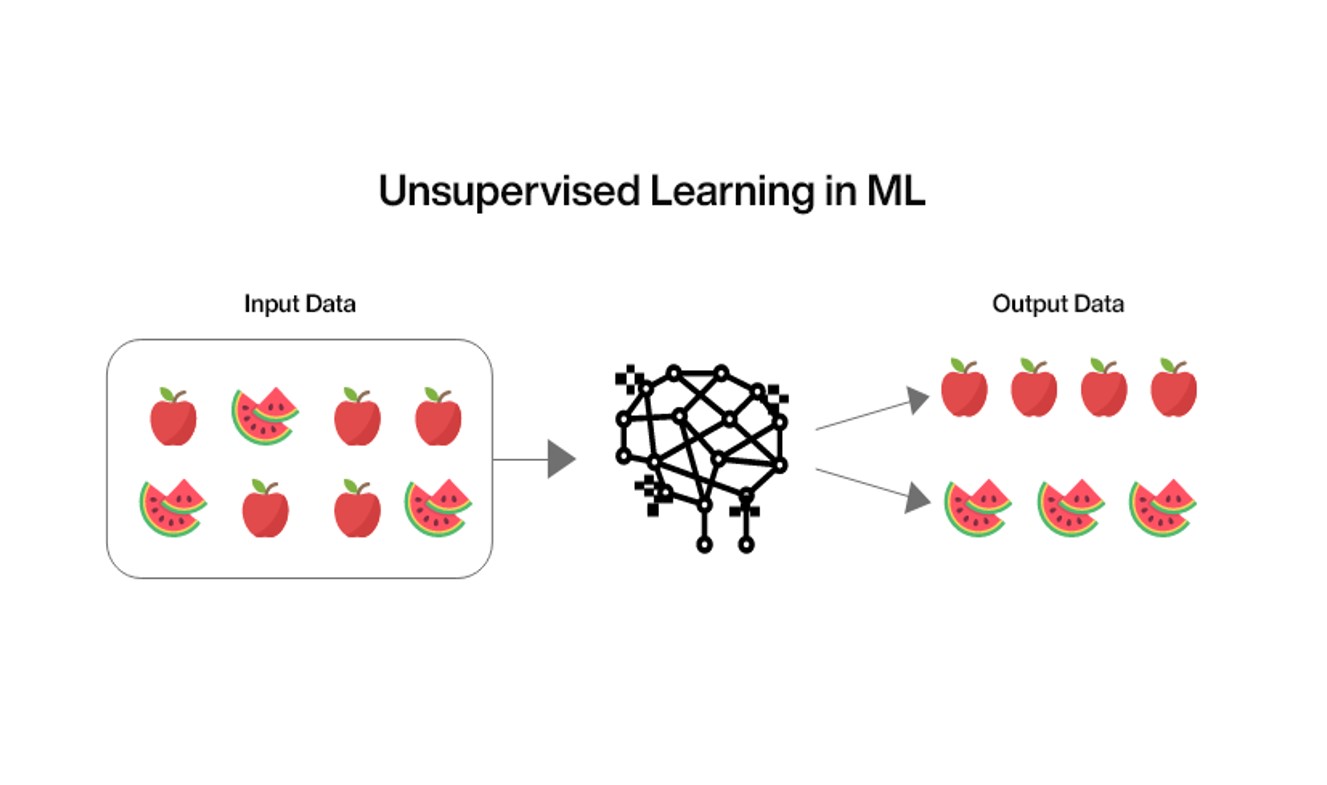
The problems that will be of focus in this task are as follows:-
- Snippet Clustering:-
- The quantity of conversation data that Salesken possesses is quite huge. And to detect patterns that otherwise stay unnoticed are recognized using different clustering techniques.
- The clustering algorithm takes pre-processed snippets as its inputs and groups them to form different clusters where each cluster signifies a unique property.
For example, let’s consider two dummy sales conversations that will be fed as input to the clustering algorithm
Conversation1
S1: Hello my name is Andy, am I speaking with Shubham.
S2: Yes it’s Shubham here, how can I help you Andy
S3: I am calling from an “xyz” company and you were looking for an “abc” product of ours.
S4: Yes, I would like to know more about it.
Conversation2
S1: Hello my name is Candy, am I speaking with Suvro.
S2: Yes it’s Suvro here, how can I help you Candy
S3: I am calling from an uvw company and you were looking for a pqr product of ours.
S4: No I just landed on the page randomly. Thanks for the call.
The output from the clustering algorithm will look something like this-
- Cluster1: [“Hello my name is Andy, am I speaking with Shubham.”, ”Hello my name is Candy, am I speaking with Suvro.”]
- Cluster2: [“Yes it’s Shubham here, how can I help you Andy”, ”Yes it’s Suvro here, how can I help you, Candy”]
- Cluster3: [“I am calling from an “xyz” company and you were looking for “abc” product of ours.”, “I am calling from an uvw company and you were looking for a pqr product of ours. ”]
- Cluster4: [“Yes, I would like to know more about it.”]
- Cluster5: [“No I just landed on the page randomly. Thanks for the call.”]
- Novel Signal Discovery:-
- Once the snippet clusters are ready they can be tagged to get a reference about the meaning each cluster conveys.
- There will be cases where the predefined signals can not be mapped with some of the formed clusters.
- These sort of clusters will give an idea about the kind of information that is not getting captured by the current set of signals defined by domain experts and hence can be added to the signal set.
- Conversation Graph Generation:-
- A conversation graph is a state transition graph that gives the probability of moving to a new state from the current state given all the previous states have occurred.
- The idea of this approach is that the clubbed snippets will usually be from a nearby timestamp of each other.
3. Few-shot Supervised Generative Models (3-6 months):-
The State of the art Language models like BERT, GPT(1,2,3) etc are usually trained on very large scale data and are capable enough to understand common NLP tasks to some extent. These models can also be fine-tuned for our downstream task with very little data. This practice of fine-tuning a machine learning model with very small amounts of training data is called Few-shot learning.
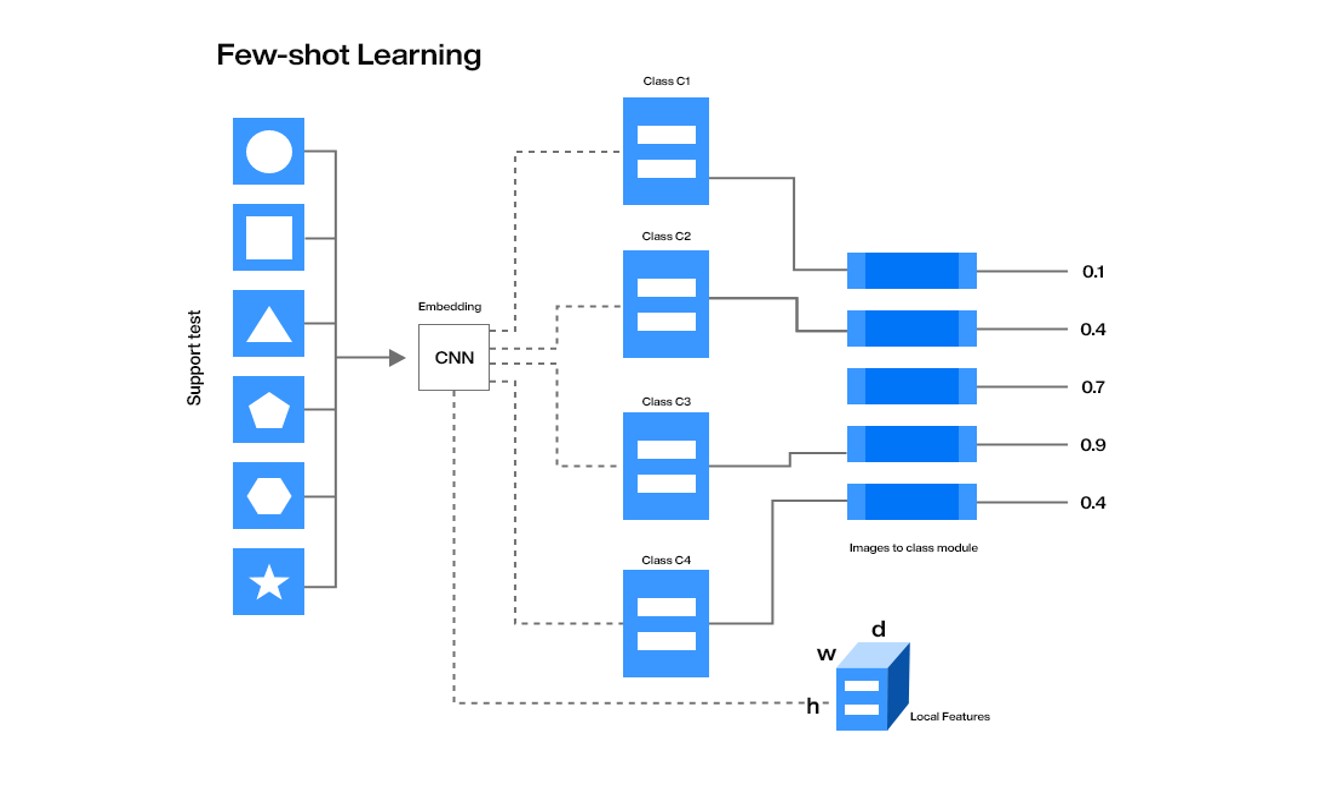
In this stage, we apply the few-shot learning technique to the generative models that are trained to generate the next sequence based on the current sequence where a sequence can be words, sentences, paragraphs etc
Different problems that will be resolved using this technique are as follows:
- Data Augmentation:-
- The process of automatically adding data to an existing dataset is called data augmentation.
- These fine-tuned few-shot generative models will be used to increase the size of existing data for a wide variety of tasks like signal generation, snippet correction etc.
- Snippet-to-Signal Generation:
- By using the clustering technique and a few-shot generative model fine-tuned to classify dimensions for a given input, we can tag the generated clusters with the playbook dimension.
- These tagged clusters can be filtered for top sentences and then these can be added back to the existing signal set.
- Snippet Lexical Simplification:
- The generative models can also be fine-tuned to give simplification of complex words in a given sentence to reduce text complexity.
- We can use such models to change snippets into their simpler form to map them with signals with ease.
- Asr correction:
- Any of the NLP task that we perform uses text and to produce that text from speech an automatic speech recognition model commonly known as ASR is used.
- But ASR systems are also prone to errors and if an error occurs at the first stage it will propagate down to any NLP task that we perform.
- To fix this problem we can use the generative model, which can correct the sentences for grammatical errors, spelling mistakes, and domain-specific word replacements.
4. Self-Supervised Generative Model (6-9months):
In this technique, we train a generative model to fill in the blanks by this, we mean that we suppress some of the parameters of the inputs also known as masking and then the model tries to predict the missing pieces. In this way, the data-dependency of the machine learning algorithm can be reduced and the model learns the task without little or no human interference.
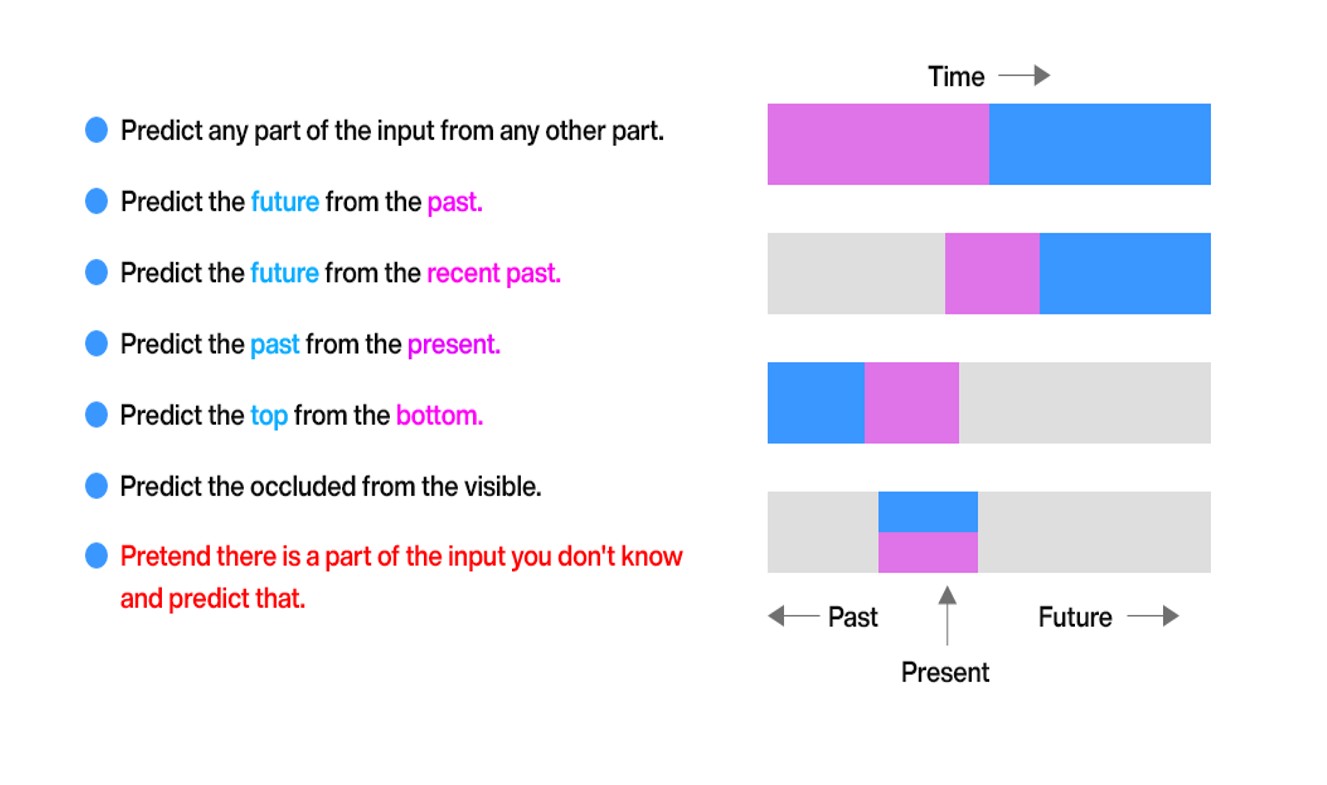
The problems that will be tackled under this technique are as follows:-
- Masked Dialogue Modelling(Sentence masking)
- This task will involve training models using the conversation data between the agents and the customer.
- The model will be trained by using the concept of sentence masking as explained above.
- Over a conversation, some of the agent snippets will be masked and the model must predict/generate based on the previous customer snippet.
- Context-Aware Dialogue Generation
- Using the technique of long attention a generative model can keep the context previous snippet turns between agent and the customer.
- Based on the context history the model will learn to predict the current response in a way human intelligence works.
5. Reinforcement Based Self-learning Agent (9-12 months):
Reinforcement learning is a machine learning approach in which the model learns a task based on some reward policy. The model will not be given any training data to learn from. Based on model output the reward value changes and the model will try to maximize the cumulative reward.
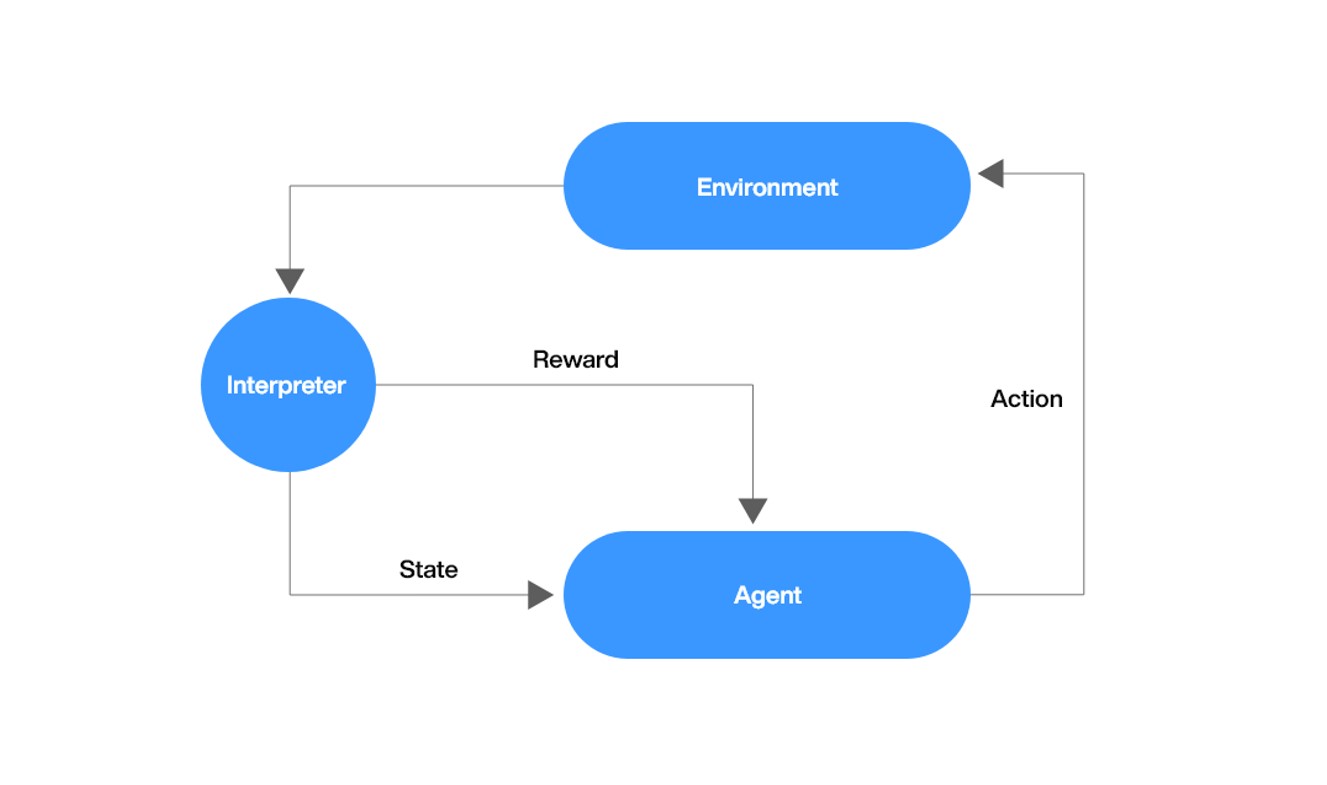
We will use two different methods to create such models:
- Adaptive Self-play
- Here a single model will try to maximize the reward of win probability of conversation.
- The model will generate conversations that converge to a won lead call.
- Multi-Agent/skill blending
- Here there will be multiple agents, two or more than two that can interact with each other.
- Each model will always listen to the other models but will only trigger an output when its required condition is fulfilled. For example, one model can mimic an agent and the other could mimic a customer
6. Agent Level Personalised Dialogue/Cue Generation(12-15 months):
The models that will be trained in the above-mentioned approaches will be used in this technique. By TextStyle Transferring these models will be tuned to act as the customs agents resembling the best performers.
These models can be used to suggest cues to the agents as and when needed.
7. AI Sales Agent(15-18 months):
In this sprint, we will polish the models created using the above-mentioned techniques to be more Goal-oriented and Schema guided.
These models will be able to adapt to the new information and patterns as the conversation data grows.
The models will be more of an Augmented Human Sales Agent than just being able to answer some questions with the ability to show empathy, conflict resolution, negotiation, and other human-like emotions.
They will also have access to the knowledge management system for accessing any information that is not known to them and adapting to that information.
Conclusion:
This RoadMap covers a wide range of problems that can be solved using different Machine learning and deep learning techniques. It will help us to make a transition from a simple sentence-similarity-based approach to more scalable generative methods.

Submit a Comment